- Author : Tomáš Mokoš, Marek Brodec
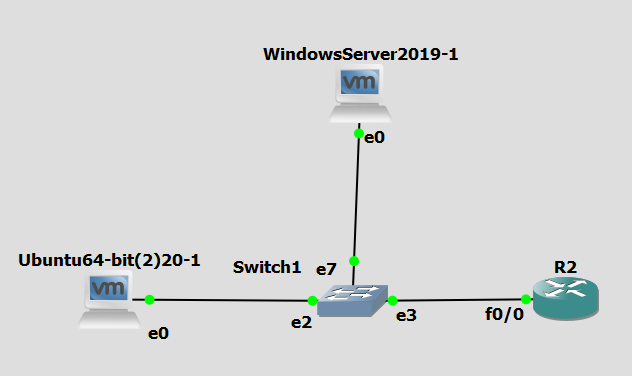
In our topology, the server running Moloch was connected to a 100Mbps switch, therefore, even though the generated network traffic reached 140Mbps, the flow was subsequently limited on switch.
Single source to single destination test
At first, while generating packets with a generated IP address from cloud to a lab PC, we have had a problem with the cloud’s security policies. These policies prevented the sending of packets with source IP address different from the one assigned to the hosting cloud instance, therefore we have only generated traffic from a single source IP address to a single destination IP address.
We have observed the volume of incoming data and its effect on performance using network monitoring tools mentioned in the previous chapters. The graphs below show that in the moment of traffic spike, CPU usage spiked as well, however it did not exceed 20%. The graph titled “Mem” shows the RAM usage of all running services including the instances of Moloch, Snort and many others with the addition of cache memory.

The following graph shows utilization of RAM allocated exclusively to Elasticsearch. Having been allocated with 25 GB of RAM, Elasticsearch uses 4.2 GB in this instance. This test revealed that Elasticsearch uses unnecessary amount of RAM and after the test we have decreased the amount of allocated RAM to 18 GB.

N sources to single destination test
The previous packet generation was not ideal because the relations had many shared characteristics. All test cases had identical IP addresses, number of packets and payload, which made indexing much easier. To approximate real network traffic as precisely as possible, we have tried to address the issue with source IP address generation. The solution was packet generation from our own laptop with OS Kali Linux running in VirtualBox as a source of attacks. The laptop was connected to our switch and generated traffic towards the lab. The packets passed through the interface which was mirrored towards our server.
Test results showed CPU utilization rise in the range from 20 to 30%.

“Heap Mem” graph shows that, of the allocated 19 GB of RAM, 6.3 GB is used .

The results revealed that the amount of allocated RAM can be further decreased, freeing up space for other processes. Graph titled “Mem” shows that all running processes use 31 GB of RAM, therefore it would be advisable to stop all unnecessary processes before testing. This, however, was not an option for us, because in parallel with us, other students have been working on their respective bachelor’s theses.
Testing evaluation
Restart of services was performed before the single source to single destination test, but service instances were not restarted before other tests. We have concluded that higher network traffic mainly influences CPU utilization. Graphs of both Elasticsearch RAM usage and overall RAM usage do not show any significant spikes during the arrival of generated test traffic. The table shows that during normal traffic (4.5 Mbps at the time), RAM usage is higher in both cases above than before the first test, where traffic was 20 times higher than normal. These two graphs are mainly affected by the time elapsed from service start and possibly the amount of captured data. These tests were performed in the same order as they were mentioned above, with one week between the individual tests. Even though the graphs indicate utilization of 31 out of 32 GB of RAM, from the 18 GB allocated to Elasticsearch, only one third is used. This can be solved by reducing the amount of RAM allocated to Elasticsearch, thus freeing up space for other processes.
Cache can be cleared by the following command:
free && sync && echo 3 > /proc/sys/vm/drop_caches && free
This drops RAM usage from 31 GB to 20 GB.
Sources
- Report Project 1-2 – Marek Brodec